GPU 硬件与 LLM 扩展
Part 12 of How To Scale Your Model (第11部分:结论 | 全文完)
虽然我们很喜欢 TPU,但 GPU 也是 LLM 训练的主力。本章深入解析 GPU——单芯片架构、多卡互联、以及 LLM 训练的扩展策略。我们会和 TPU 做大量对比,帮你建立完整的理解框架。本节建立在第2章 TPU和第5章训练的基础上。
GPU 是什么?
一句话总结:GPU 是一堆小而灵活的计算单元(SM)连到一块大内存(HBM)。和 TPU 相比,GPU 更灵活但更难优化到极致。
先看一张图:
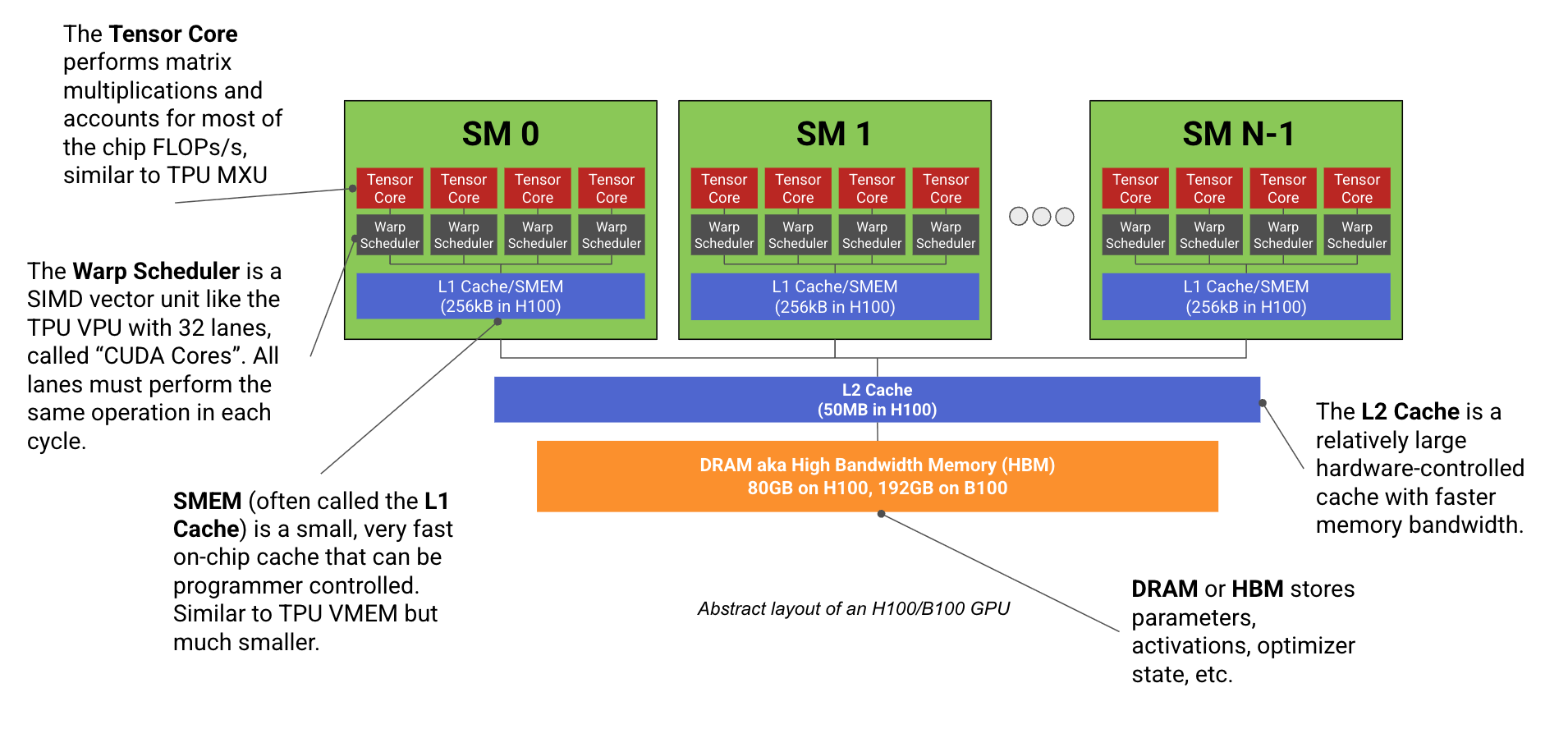
核心组件对照表:
| GPU 术语 | TPU 术语 | 干什么的? |
|---|---|---|
| SM(流式多处理器) | TensorCore | 核心计算单元,包含下面的子单元 |
| Tensor Core | MXU | 做矩阵乘法的硬件 |
| Warp 调度器 + CUDA 核心 | VPU + ALU | 做向量运算(ReLU、加法等) |
| SMEM(共享内存) | VMEM | 快速片上缓存 |
| HBM(全局内存) | HBM | 大容量主内存 |
GPU vs TPU 的核心区别:
| 对比维度 | GPU (H100) | TPU (v5p) |
|---|---|---|
| 计算单元数量 | 132 个 SM(小而多) | 2 个 TensorCore(大而少) |
| 编程模型 | SIMT(更灵活) | SIMD(更简单) |
| 快速缓存 | 32MB SMEM(分散) | 128MB VMEM(集中) |
| 调度方式 | 多线程,硬件调度 | 单线程,编译器调度 |
| 优化难度 | 高(太多旋钮) | 中(编译器负责更多) |
SM 内部结构
让我们放大看一个 SM:
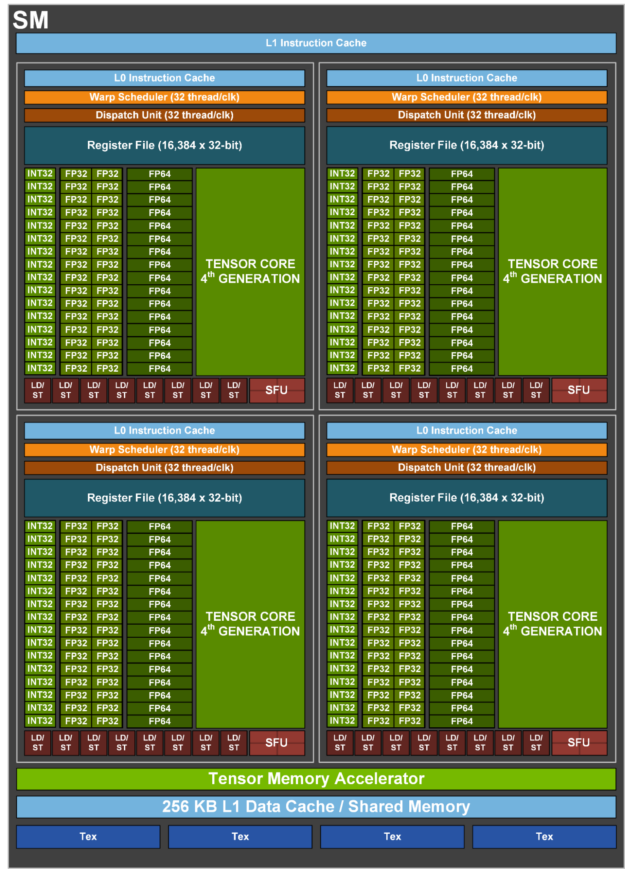
每个 SM 分成 4 个子分区,每个包含:
| 组件 | 数量 | 作用 |
|---|---|---|
| Tensor Core | 1 | 矩阵乘法(绝大部分 FLOPs 来源) |
| CUDA 核心 | 32 (fp32) | 向量运算(ReLU、逐点操作) |
| 寄存器 | 16K × 32位 | 每个线程的本地存储 |
Tensor Core 是 FLOPs 的主力:
H100 的 990 TFLOPs/s 几乎全来自 Tensor Core,CUDA 核心只贡献约 66 TFLOPs/s(忽略 FMA)。
每个 Tensor Core 每周期能做约 1024 个 bf16 FLOPs,相当于一个 8×8×8 的小 matmul:
- V100: 256 FLOPs/周期
- A100: 512 FLOPs/周期
- H100: 1024 FLOPs/周期
- B200: 约 2048 FLOPs/周期
CUDA 核心比 VPU 更灵活:
GPU 使用 SIMT(单指令多线程)而不是 TPU 的 SIMD:
- 每个 CUDA 核心(”线程”)有自己的指令指针
- 可以独立编程,但分歧会降低效率
- 能访问不连续内存,维护每线程状态

调度也更灵活:
每个 SM 可以同时调度最多 64 个 warp(程序),硬件自动在等待内存时切换。TPU 是单线程的,全靠编译器流水线化。
内存层级
| 层级 | H100 容量/SM | H100 总容量 | 带宽 | 类比 TPU |
|---|---|---|---|---|
| 寄存器 | 256kB | 32MB | 超快 | VRegs |
| SMEM/L1 | 256kB | 32MB | 很快 | VMEM |
| L2 缓存 | - | 50MB | ~5.5TB/s | 无 |
| HBM | - | 80GB | 3.35TB/s | HBM |
几个关键点:
- L2 缓存是共享的:所有 SM 共享 50MB L2,但不由程序员直接控制,访问模式影响性能
- TPU 快速缓存更大:TPU 有 128MB VMEM vs GPU 的 32MB SMEM,且 VMEM 带宽更高(~40TB/s)
- B200 新增 TMEM:因为 Tensor Core 变大了,需要额外的内存空间来存累加器
GPU 规格速查
内存容量:
| GPU | 代次 | SM 数 | SMEM/SM | L2 | HBM |
|---|---|---|---|---|---|
| V100 | Volta | 80 | 96kB | 6MB | 32GB |
| A100 | Ampere | 108 | 192kB | 40MB | 80GB |
| H100 | Hopper | 132 | 256kB | 50MB | 80GB |
| H200 | Hopper | 132 | 256kB | 50MB | 141GB |
| B200 | Blackwell | 148 | 256kB | 126MB | 192GB |
计算能力和带宽:
| GPU | HBM 带宽 | bf16 FLOPs/s | fp8 FLOPs/s | fp4 FLOPs/s |
|---|---|---|---|---|
| V100 | 900GB/s | — | — | — |
| A100 | 2.0TB/s | 312T | 624T | — |
| H100 | 3.4TB/s | 990T | 2000T | — |
| H200 | 4.8TB/s | 990T | 2000T | — |
| B200 | 8.0TB/s | 2250T | 4500T | 9000T |
GPU vs TPU:芯片级对比
| 维度 | GPU (H100) | TPU (v5p) | 影响 |
|---|---|---|---|
| 计算单元 | 132 个小 SM | 2 个大 TensorCore | GPU 更灵活,TPU 更易优化 |
| 向量单元 | 528 个 Warp 调度器 | 8 个 VPU slot | GPU 并行度更高 |
| 快速缓存 | 32MB SMEM | 128MB VMEM | TPU 缓存更大 |
| 寄存器 | 32MB | 256kB | GPU 寄存器更多 |
| Tensor Core/MXU | 528 个 | 8 个 | GPU 更细粒度 |
GPU 更模块化:每个 SM 独立,可以同时跑不同任务。但这也意味着需要仔细协调 L2 缓存使用。
TPU 更集中:编译器负责流水线化和调度,程序员写的代码更直接映射到硬件。
历史包袱:GPU 是从图形渲染演化来的,不是专门为 ML 设计的。这既是灵活性的来源,也是复杂性的根源。
测验 1:GPU 硬件
问题 1 [CUDA 核心数量]:H100 有多少 fp32 CUDA 核心?TPU v5p 有多少 VPU ALU?
点击查看答案
H100:132 SM × 4 子分区 × 32 核心 = 16,896 个 CUDA 核心
B200:148 × 4 × 32 = 18,944 个
TPU v5p:2 TensorCore × 1 VPU × (8 × 128) 通道 × 4 ALU = 8,192 个 ALU
GPU 的向量通道数约是 TPU 的 2 倍,但 FLOPs 能力差不多。
问题 2 [向量 FLOPs]:H100 有多少向量 fp32 FLOPs/s?和 Tensor Core 比如何?
点击查看答案
132 × 4 × 32 × 1.59GHz = 26.9 TFLOPs/s
Boost 频率下约 33.5 TFLOPs/s。
Tensor Core 的 990 TFLOPs/s 是向量的约 30 倍!
问题 3 [临界强度]:H100 的 fp16 matmul 临界强度是多少?B200 呢?
点击查看答案
H100:990e12 / 3.35e12 = 295
B200:2250e12 / 8e12 = 281
和 TPU 的 240 很接近。这意味着批次大小需要约 280 才能计算受限。
问题 4 [Matmul 时间]:B200 上 fp16[64, 4096] × fp16[4096, 8192] 需要多久?[512, 4096] × [4096, 8192] 呢?
点击查看答案
临界批次大小是 281,所以:
[64, 4096]:带宽受限。读写 2×64×4096 + 2×4096×8192 + 2×64×8192 = 69MB,耗时 69MB / 8TB/s ≈ 8.6us。实际约 10-12us。
[512, 4096]:计算受限。2×512×4096×8192 / 2.3e15 = 15us。实际约 20us。
问题 5 [缓存容量]:H100 总共有多少 L1/SMEM?和 TPU VMEM 比如何?
点击查看答案
132 × 256kB = 33MB SMEM,再加 33MB 寄存器,共 66MB。
TPU 有 128MB VMEM(是 GPU 的 2 倍),而且延迟更低。TPU 只有 256kB 寄存器(因为溢出到 VMEM 很快)。
问题 6 [计算时钟频率]:NVIDIA 说 B200 能做 80 TFLOPs/s 向量 fp32。假设每核心每周期 2 FLOPs (FMA),估算时钟频率。
点击查看答案
148 × 4 × 32 = 18,944 核心,每周期 18,944 × 2 = 37,888 FLOPs
时钟频率 = 80e12 / 37,888 = 2.1 GHz
液冷的 B200 确实能跑这么高。
问题 7 [向量加法时间]:两个 fp32[N] 向量相加需要多久?
点击查看答案
读写 3 × 4 × N = 12N 字节,做 N 次加法。
算术强度 = N / 12N = 1/12,远低于临界强度 10,所以是带宽受限的。
运行时间 = 12N / 3.35e12 = N / 2.8e11
-
N = 65,536:理论 0.23us,实际 ~1.5us(延迟受限) -
N = 1G:理论 3.84ms,实际 ~4.1ms(接近 roofline)
网络拓扑
一句话总结:GPU 用树状交换网络(NVLink + InfiniBand),TPU 用 3D 环面。GPU 节点内带宽高,节点外带宽受限;TPU 带宽在各个方向更均匀。

GPU vs TPU 网络对比:
| 维度 | GPU | TPU |
|---|---|---|
| 拓扑 | 树状交换(NVLink + IB) | 3D 环面 |
| 节点内 | 全连接,450GB/s | 直连邻居,540GB/s |
| 节点外 | 交换网络,400GB/s | 沿环面路由 |
| 扩展性 | 需要更多交换机 | 直接加芯片 |
| 带宽一致性 | 节点内 > 节点外 | 各方向均匀 |
节点内:NVLink

NVLink 规格演进:
| 代次 | GPU | 链接带宽 | 端口数/GPU | 总带宽/GPU | 节点大小 |
|---|---|---|---|---|---|
| 3.0 | Ampere | 25GB/s | 12 | 300GB/s | 8 |
| 4.0 | Hopper | 25GB/s | 18 | 450GB/s | 8 |
| 5.0 | Blackwell | 50GB/s | 18 | 900GB/s | 8/72 |
关键数字:
- H100 节点:8 GPU,每 GPU 450GB/s,总 3.6TB/s
- GB200 NVL72:72 GPU,每 GPU 900GB/s,总 32.4TB/s
测验 2:GPU 节点
问题 1 [节点总带宽]:8xH100 节点的总带宽是多少?
点击查看答案
NVSwitch 带宽:4 × 64 × 25GB/s = 6.4TB/s
GPU 出口瓶颈:8 × 450GB/s = 3.6TB/s
实际带宽 = 3.6TB/s(受 GPU 出口限制)
问题 2 [二分带宽]:8xH100 节点的二分带宽是多少?
点击查看答案
把节点分成两半,每半 4 个 GPU。
每 GPU 可以向另一半发送 450GB/s,双向共 8 × 450GB/s = 3.6TB/s。
NVIDIA 官方报告也是这个数字。
问题 3 [AllGather 时间]:8xH100 上 AllGather(bf16[DX, F]),D=4096, F=65536,需要多久?
点击查看答案
总字节 = 4096 × 65536 × 2 = 512MB
环形算法:每 GPU 出口 B×(N-1)/(N×W) = 512MB × 7 / (8 × 450GB/s) ≈ 1.0ms
实际约 1.5ms(有延迟开销)。
节点外:InfiniBand

网络层级:
| 层级 | GPU 数 | 交换机类型 | 每 GPU 带宽 | 备注 |
|---|---|---|---|---|
| 节点 | 8 | NVSwitch | 450GB/s | 全连接 |
| SU(叶) | 256 | IB 叶交换机 | 50GB/s | 32 节点 |
| SuperPod(脊) | 1024 | IB 脊交换机 | 50GB/s | 4 个 SU |
胖树拓扑:设计保证任意两节点间 400GB/s 带宽(全二分带宽)。
GB200 NVL72 的变化:

| 节点类型 | GPU/节点 | GPU 出口 | 节点出口 |
|---|---|---|---|
| H100 | 8 | 450GB/s | 400GB/s |
| B200 | 8 | 900GB/s | 400GB/s |
| GB200 NVL72 | 72 | 900GB/s | 3600GB/s |
要点:GB200 NVL72 把节点变成 72 GPU,节点出口带宽也成比例增加到 3.6TB/s。
测验 3:跨节点网络
问题 1 [验证胖树]:证明 1024 GPU SuperPod 在每个层级都有全二分带宽。
点击查看答案
节点级:每节点 8 × 400Gbps = 400GB/s 出口
叶级:每叶交换机 64 × 400Gbps / 2 = 12.8TB/s(一半入口一半出口),服务 32 节点 = 400GB/s/节点
脊级:16 × 64 × 400Gbps = 51.2TB/s,服务 128 节点 = 400GB/s/节点 ✓
问题 2 [扩展到 2048/4096 GPU]:如何扩展?
点击查看答案
2048 GPU:加倍脊交换机(32 个),或减半叶-脊链接数
4096 GPU:端口用完了,需要加一层核心交换机(128 脊 + 64 核心)
GPU 上的集合通信
节点内集合操作
AllGather/ReduceScatter:环形算法
\[T_\text{AG/RS} = \frac{B \cdot (N-1)}{N \cdot W_\text{GPU出口}} \approx \frac{B}{W_\text{GPU出口}}\]- H100:
B / 450GB/s - B200:
B / 900GB/s
AllReduce = ReduceScatter + AllGather = 2× 成本

AllToAll:节点内全连接,直接发送
\[T_\text{AllToAll} = \frac{B \cdot (N-1)}{N^2 \cdot W} \approx \frac{B}{N \cdot W}\]比 TPU 快 2 倍(TPU 是 B / 4W,GPU 是 B / 8W)。
实测 vs 理论:

SHARP(网络内归约):

理论上 AllReduce 成本减半,实际只有约 30% 改进:

跨节点集合操作
胖树保证全二分带宽:任意两节点间 400GB/s
\[T_\text{AG/RS} = \frac{B}{W_\text{节点出口}} = \frac{B}{400\text{GB/s}}\]AllToAll 跨节点变慢:不能利用胖树的分层带宽
\[T_\text{AllToAll} = \frac{B \cdot (M-1)}{M^2 \cdot W_\text{节点出口}} \approx \frac{B}{M \cdot 400\text{GB/s}}\]从 1 节点到 2 节点,AllToAll 成本增加 4 倍以上!
多轴分片时的归约:
当数组同时在 X 和 Y 轴分片时,$\text{AllReduce}_X(A[I_Y, J]{U_X})$:
- 如果 Y 跨越多节点:成本降低 Y 倍
- 如果 Y 在节点内:节点级成本降低,但总成本可能不变
要点:跨节点 AG/RS 成本约 B / 400GB/s,AllReduce 是 2 倍(除非有 SHARP)。AllToAll 跨节点代价很高!
测验 4:集合操作
问题 1 [SU AllGather 字节]:在 AllGather 期间,节点级交换机和脊交换机各处理多少字节?
点击查看答案
节点级交换机:
- 入口:
N × B/MN = B/M字节 - 出口:
B/M到脊 +N × (B - B/MN) = NB - B/M到 GPU
脊交换机:
- 入口:
M × B/M = B字节 - 出口:
M × B(M-1)/M = B(M-1)字节
问题 2 [单节点 SHARP AllReduce]:使用 SHARP 时交换机处理多少字节?
点击查看答案
- 每 GPU 发送
B(N-1)/N,交换机入口B(N-1) - 交换机累积后发回
B/N给每 GPU,出口B - GPU 完成残差归约后再发回,入口
B - 交换机多播结果,出口
B(N-1)
总共:入口 BN,出口 BN
GPU 上 LLM 扩展的 Roofline 分析
本节分析各种并行策略在 GPU 上的 Roofline,确定什么时候计算受限、什么时候通信受限。
关键带宽数字:
| 节点类型 | GPU/节点 | GPU 出口带宽 | 节点出口带宽 |
|---|---|---|---|
| H100 | 8 | 450GB/s | 400GB/s |
| B200 | 8 | 900GB/s | 400GB/s |
| GB200 NVL72 | 72 | 900GB/s | 3600GB/s |
我们用 $W_\text{collective}$ 表示相关带宽(节点内用 GPU 出口,跨节点用节点出口)。
数据并行
DP/FSDP 的通信:反向传播中的 AllReduce 或 RS+AG
\[T_\text{math} = \frac{8 \cdot BDF}{X \cdot C}\] \[T_\text{comms} = \frac{8 \cdot DF}{W_\text{collective}}\]要计算受限:
\[\frac{B}{X} > \frac{C}{W_\text{collective}}\]临界批次大小/GPU:
| 场景 | H100 | B200 |
|---|---|---|
| 节点内 | 2200 | 2500 |
| 跨节点 | 2475 | 5625 |
MoE 模型:临界批次大小乘以 E/k(专家数/每token专家数)
例如 E=128, k=4 → 需要 32× 更大的批次大小!
要点:数据并行需要每 GPU 约 2500 token 批次才能计算受限。MoE 需要 E/k 倍更多。
张量并行
TP 需要在激活上 AllGather/ReduceScatter,和 MLP FLOPs 重叠:
\[T_\text{math} = \frac{4 \cdot BDF}{Y \cdot C}\] \[T_\text{comms} = \frac{4 \cdot BD}{W_\text{collective}}\]要计算受限:
\[Y < \frac{F \cdot W_\text{collective}}{C}\]最大 TP 并行度:
| 场景 | 公式 | LLaMA-3 (F=28672) |
|---|---|---|
| 节点内 | F / 2200 | ~13 |
| 跨节点 | F / 2475 | ~11 |
实际通常限制在 8 路 TP(单节点)或最多 16 路(2 节点,有 2× 带宽加成)。
要点:张量并行当 Y > F/2475 时通信受限,通常限于 8 路。
专家并行
MoE 用 AllToAll 发送 token 到对应专家:
\[T_\text{math} = \frac{4 \cdot B \cdot k \cdot D \cdot F}{Z \cdot C}\] \[T_\text{comms} = \frac{4 \cdot B \cdot D \cdot (Z-8)}{Z \cdot W} \cdot \min\left(\frac{8k}{Z}, 1\right)\]两种可行域:
- 小规模 EP(~2 节点):任意 F
- 大规模 EP:需要 F > 8 × C/W(约 20000)
DeepSeek v3(F=2048)只能做有限的 EP。
要点:F < 20000 时 EP 限于 1-2 节点;F > 20000 时可做大规模 EP。
流水线并行
PP 的通信成本极低(只在阶段边界传递微批次激活):
\[T_\text{per-layer comms} \approx 1.5 \cdot \frac{2BD}{W \cdot N_\text{layers}}\]除以层数,成本可忽略。
为什么不全用 PP?
- 代码复杂:微批次调度难以自动化
- 和 FSDP 冲突:ZeRO-3 需要在每个微批次 AllGather,成本太高
- 流水线气泡:需要零气泡调度技巧

要点:PP 通信成本低,但代码复杂且和 FSDP 冲突。
实战案例
DeepSeek v3(2048 H800 GPU):
- 64 路专家并行(8 节点)
- 16 路流水线并行
- 2 路 ZeRO-1 数据并行
- 批次大小:6300 万 token(每 GPU 30k)
LLaMA-3 405B(16000 GPU):
- 8 路张量并行(节点内)
- 16 路流水线并行
- 128 路 ZeRO-1 数据并行
- 批次大小:1600 万 token(每 GPU 1k)
GPU LLM 扩展总结
| 策略 | 临界条件 | 典型范围 |
|---|---|---|
| DP/FSDP | 每 GPU ≥ 2500 token | 任意 |
| TP | Y ≤ F / 2475 | ≤ 8 路 |
| EP | 取决于 F | 2 节点或大规模 |
| PP | 几乎无限制 | 需要复杂调度 |
分片配方:
- 小稠密模型:激进 FSDP + 一点 TP/PP
- 大稠密模型:1-2 节点 TP + 多节点 PP + 纯 DP
- MoE:能做多少 EP 取决于 F;通常需要 PP
测验 5:LLM Roofline
问题 1 [B200 Roofline]:B200 的 FLOPs 是 H100 的 2.25 倍,节点内带宽是 2 倍,但节点外带宽不变。这如何影响 Roofline?
点击查看答案
节点内:临界强度 2250e12 / 900e9 = 2500,和 H100 差不多
节点外:临界强度 2250e12 / 400e9 = 5625,比 H100 高很多!
结论:B200 在跨节点场景更难计算受限。GB200 NVL72 通过增加节点出口带宽解决这个问题。
问题 2 [LLaMA-3 70B 分片]:
- 最少需要多少 H100?
- 4096 GPU 45% MFU,训练 15T token 需要多久?
- F=28672,批次 400 万,如何分片?
点击查看答案
-
权重 2B + 优化器 8B = 700GB,需要 9 GPU,实际至少 2 节点
-
总 FLOPs =
6 × 70e9 × 15e12 = 6.3e24每秒 =4096 × 990e12 × 0.45 = 1.8e18时间 = 3.5e6 秒 = 40 天 -
TP 限制:节点内
F / 1995 ≈ 14,可做 8 路节点内 TP- 纯 DP:512 路 DP,但每 GPU 需存
700GB / 8 = 87.5GB,超出 80GB 显存,不行 - ZeRO-3 + 8 路 TP:512 路 ZeRO-3,每 GPU 批次 =
4M / 4096 = 976token,远低于临界值 2200(而且 ZeRO 需搬权重,实际临界值翻倍),通信受限 - 8 路 PP:模型分片跨 8 节点,AllGather 带宽提升到
8 × 400 = 3200 GB/s,临界值 =990e12 / 3200e9 ≈ 309,可行!
- 纯 DP:512 路 DP,但每 GPU 需存
问题 3 [MoE 分片]:256 专家,k=4,F=2048,D=8192 的 400B MoE 如何分片?
点击查看答案
TP 限制:F × 450e9 / 990e12 = 0.9,任何 TP 都通信受限!
EP 在跨节点时:需要 k × F > 19800,即 4 × 2048 = 8192 < 19800,EP 也受限!
只能做 PP + 纯 DP。这就是为什么小 F 的 MoE 很难训练。
问题 4 [DeepSeek v3 分析]:256 专家,k=8,F=2048,D=7168。为什么选择 64 EP + 16 PP + 2 DP?
点击查看答案
H800 带宽 300GB/s(低于 H100)
TP 限制:F × 300e9 / 990e12 = 0.6,不可行
EP 在 Z=64 时:F > 2.5(推导见原文),刚好可行!
64 EP × 16 PP × 2 DP = 2048 GPU ✓
注意他们正好踩在 EP 限制线上!
致谢与延伸阅读
感谢 Vedant Sarkar、Jared Davis、Karan Desai 的反馈,以及 Tian Zheng、Yifeng Lu、Zixuan Jiang、Yunpeng Liu 指出基准测试错误。
延伸阅读:
- NVIDIA 架构白皮书
- CUDA 编程指南
- SuperPod 网络指南
- NCCL 文档
- Chips and Cheese - GPU 微架构分析
- GPU Mode - GPU 编程视频
附录
附录 A:GB200 的变化
GB200 NVL72 有 72 GPU 节点和 3.6TB/s 节点出口,显著改变 Roofline:
TP:Y < F / 2500,约 11 路(可用 8 路,因为 72 的因子)
DP:
- 节点内:
2250e12 / 900e9 = 2500 - 节点外:
2250e12 / 3600e9 = 625
节点级变成瓶颈!
附录 B:更多网络细节
TPU vs GPU 达峰速度:

TPU 在更小消息时就能达到峰值带宽,延迟开销更小。
参差 AllToAll 理论:
成本 = (1 - ((Z-1)/Z)^K) × (Z-1)/Z × B / (W×Z)
K 次随机选择中不同结果的期望数,近似 min(k/Z, 1)。
IB 链接编码:64B/66B 编码,400Gbps 实际有效 388Gbps。NVIDIA 报告原始数字。